


Frenar el desarrollo de IA por seis meses: ¿es posible/deseable?
Leé hasta el final para ver un análisis de las sonrisas que dibujan las IAs

Hay una declaración reciente de OpenAI en referencia a la inteligencia general artificial (AGI) en la que dicen que “en algún punto, puede que sea importante hacer análisis independientes antes de empezar a entrenar sistemas futuros (…)”. Estamos de acuerdo. Ese punto es ahora.
Por lo tanto, llamamos a todos los laboratorios de IA para que inmediatamente pausen por al menos seis meses el entrenamiento de sistemas más poderosos que GPT-4. Esta pausa debería ser pública y verificable, e incluir a todos los actores claves. Si una pausa semejante no puede hacerse rápidamente, los gobiernos deberían meterse e instituir una moratoria.
“Pausen las investigaciones de IA Gigante: Una carta abierta” (link).
No recuerdo cuándo fue la última vez que algo que no sea un desarrollo técnico haya generado tamaño debate en el mundillo de datos: tanto ruido, que hasta llegó a los medios más tradicionales (al menos en Argentina).
Pero el asunto tiene unas cuantas aristas interesantes para desarmar, así que vamos desde el principio.
¿Quién le pone la firma al futuro?
Todo empezó cuando un instituto llamado Future of Life publicó una carta abierta en la cual hacen un llamamiento a detener la producción de investigación en IA avanzada, por los riesgos latentes vinculados a la inteligencia artificial generativa. De una forma extremadamente amplia, la idea es detener su desarrollo (o al menos pausarlo) por un tiempo, hasta que se pueda garantizar la seguridad en su implementación a gran escala.
¿Hasta acá vamos bien? Perfecto, porque acá terminó la parte “sencilla” del asunto.
Ni bien se dio a conocer esto, el primer punto que llamó fuerte la atención fueron las personas que firmaron esta carta. Gente como:
Elon Musk, Caprichoso-en-jefe de la Internet, quien dicho sea de paso, fue fundador también de OpenAI,
Yoshua Bengio, investigador de IA prestigiosísimo de quien ya hablé hace unos envíos,
Steve Wozniak, cofundador de Apple y actual filántropo,
entre otros investigadores y personas muy “llamativas”, tales como investigadores de DeepMind, o CEOs de empresas como Pinterest o Getty Images, entre otrxs.
Pero al toque también se supo que figuraron firmas como las de Yann LeCun, otro prócer de la IA, que en realidad fueron apócrifas: el mismísimo LeCun salió a desmentirlo, acusando a la iniciativa de ser algo cercano a la actitud de la iglesia, que buscaba una caza de brujas en contra de la ciencia y el conocimiento.
Yo llegué a entrar al sitio cuando recién se dio a conocer esta carta y estaba la opción de firmarlo, pero ahora está dado de baja, argumentando “exceso de tráfico”. Si bien no corroboré en primera mano cuán fácil o difícil era en efecto firmar (confieso que ví la firma del tío Elon arriba de todo e inmediatamente dije “esto tengo que estudiarlo un poquito mejor”), en algunos sitios se referían al sistema de adhesión digital como “un change.org glorificado”, lo que me da a entender que no era difícil falsificar ciertas firmas.

Y hay otro punto interesante para mencionar, que es la filosofía detrás de Future of Life, una corriente que algunos llaman longtermism (largoplacismo, si tuviera que traducirlo).
No me voy a meter muy de lleno en eso porque el newsletter va a ser eterno, pero muy brevemente, es una postura donde partiendo de una idea noble como la protección de futuras generaciones y el “desarrollo del total potencial humano”, se puede acercar a posturas un poco más polémicas donde el presente tal vez no importe tanto.
Dicho en otros términos, hambre para hoy, pan para mañana. En aras del potencial humano y llevar a nuestra especie a su máxima expresión, el fin justifica los medios: se hará lo necesario para llegar hasta ese “futuro ideal”.
No detenga su motor
Volviendo a la carta, en el mundo de datos/IA/ética se armó un debate bastante movido, así que voy a dar mi punto de vista a medida que resumo un poco la discusión.
Para empezar, estoy de acuerdo en que parar, en sí mismo, es imposible. Hay muchos intereses, mucha geopolítica, mucha plata y en algún punto —como persona de ciencia que me considero— entiendo de dónde viene la comparación de “no seguir para adelante” con el oscurantismo medieval.
Pero lo que creo que no se termina de percibir es que por imposible que es lo que se pide —y lo sospechoso que es quiénes lo piden, en algunos casos— , hay algo muy urgente e importante que está detrás de todo, un pedido de auxilio que podés leer entre líneas: el hecho inexorable de que todo va demasiado rápido.
Partiendo del hecho de que todo el debate está muy teñido de subjetividades (un título de sociología para decir esto), quiero mencionar que en ambas posturas en esta discusión hay tanto gente que me parece muy copada como gente que me parece muy polémica.
Por ejemplo, el fundador de Coursera y Deeplearning.ai, Andrew Ng (que como he dicho, es un tipo al cual respeto un montón) me sorprendió cuando argumentó estar en contra porque, básicamente, “el progreso nunca puede detenerse”.
No hay forma realista de implementar una moratoria a menos que los gobiernos intervengan, y que los gobiernos pausen tecnologías que no entienden es anti competitivo (…). La amplia mayoría de los equipos (tristemente, no todos), se toman el desarrollo de IA responsable y segura de forma responsable. Una moratoria de seis meses no es una propuesta práctica. Para hacer que avance la IA, deberían haber regulaciones sobre transparencia y auditoría. (link)
Y si bien en el sentido más abstracto estoy de acuerdo con lo que plantea, lo que más bronca me da de esta postura tan estúpidamente inocente lo puedo resumir con una imagen:

Ese es el “paper técnico” (las comillas son re intencionales) de GPT-4. Según dijo la gente que tuvo la paciencia de leerlo de punta a punta, es un panfleto publicitario de 94 páginas en el que, como bien aclaran en la imagen que ves arriba, no hay ningún detalle de con qué lo entrenaron, cuánto costó en términos económicos y ambientales, ni ningún otro detalle que nos permita dimensionar el costo real de esta herramienta hasta ahora casi-gratuita.
Es fuerte que empresas así se pueden dar el lujo de publicar papers así, carentes de todo, argumentando que “el panorama competitivo y las implicancias de seguridad de modelos a gran escala” lo hacen necesario.
Entonces cuando Andrew Ng dice que frenar todo por seis meses no es una propuesta práctica (que tiene razón, no lo es), ¿por qué gente como él no empuja más a hacer COSAS CONCRETAS para generar esos espacios de auditoría y supervisión que tanto necesitamos?

Fingir demencIA
Inclusive cuando comparto el argumento de fondo de la carta —la idea de que todo está yendo demasiado rápido y sería saludable parar un poco la máquina y pensar las consecuencias de lo que estamos haciendo—, me parece absolutamente inaceptable que sea firmada por gente que ya podría estar haciendo algo y no lo hace.
Cuando ves con detenimiento lo que dicen, la pregunta que aparece inmediatamente a continuación es: si la tecnología en efecto ya llegó muy lejos, ¿por qué frenar los intentos de superar a GPT-4, sin evaluar la posibilidad de sacar lo que ya está en el mercado?
Italia, por ejemplo, baneó ChatGPT en todo su territorio porque no se atañe a las leyes de protección de la GDPR. Y aclaro que no sé si me parece bien o mal esta decisión, pero por lo pronto me parece entendible: no sólo hubo importantes brechas de seguridad en el producto, con usuarixs que pudieron ver las conversaciones de otras personas (recordemos que hay gente que lo usa de psicólogo), sino que desde la entidad reguladora afirman que hasta se vieron vulnerados datos de menores.
Estos algoritmos pasaron de ser papers e ideas fantásticas, un sueño húmedo de la ciencia ficción, a ser productos sencillos de utilizar y al alcance de la mano de cualquiera en literalmente menos de cuatro meses. El problema no está en la investigación y desarrollo en sí, sino en la forma en que las empresas convierten sus frutos en productos y los lanzan al mercado sin pensar en las consecuencias posibles (e imprevistas).
A esto se refieren investigadorxs como Emily Bender, profesora de lingüística en la Universidad de Washington, quien plantea que “los riesgos y daños nunca estuvieron en ‘las IAs demasiado poderosas’ sino en la concentración de poder, la reproducción de los sistemas de opresión y el daño a los ecosistemas de información y naturales (a través del consumo prolífico de recursos energéticos) que estas tecnologías habilitan”.
El daño ya está hecho. Hoy en día estos conocimientos ya se democratizaron al punto tal que “““““cualquiera”””” (nótese la cantidad de comillas) puede usarlos y hacer algo con esto. El mundo, desde noviembre de 2022, es otro. Y no podemos ir en contra de ese hecho tan concreto como inexorable.
Lo escuchaba a Fernando Schapachnik, director de la Fundación Sadosky, hablar en la radio de la latente necesidad de “poner un cupo humano” en las organizaciones para garantizar el acceso a fuentes laborales post implementación de tanta IA, y me recorrió un escalofrío por la espalda por pensar que tal vez sí empiecen a ser necesarias esta clase de medidas...
… en tanto sigamos con esta forma de organizarnos. En tanto la forma de nuestra sociedad sea esta. En tanto las megacorporaciones capaces de hacer, pensar y poner esta clase de desarrollos tecnológicos al alcance masivo en cuestión de semanas, sigan teniendo la capacidad de hacer con el tejido social lo que se les cante, sin que haya ninguna clase de criterio ni control.
No se puede parar la investigación (porque aparte nadie lo haría: no es ilógico afirmar que es virtualmente imposible en la actualidad que todas las naciones se pongan de acuerdo en algo semejante), pero lo que sí se puede hacer es evitar que las empresas saquen productos con esta clase de modelos de IA al mercado.
Esta sí sería una acción concreta, una propuesta práctica, un buen primer paso para el desarrollo de tecnologías con las necesidades sociales en mente, y no las de la expansión perpetua de un mercado.
Creo que el mejor resumen de lo compleja que es la situación es esta frase de Casey Newton, editor de Platformer:
No sé si eventualmente la IA va a desatar el caos que algunos alarmistas están prediciendo. Pero sí creo que es mucho más probable que esos riesgos ocurran si la industria se sigue moviendo a toda velocidad. Ralentizar el lanzamiento de grandes modelos de lenguaje no es una respuesta completa para resolver este problema. Pero nos puede dar la chance de desarrollar una.
¡Hasta la próxima!
¡Gracias por haber llegado hasta acá! Arranco con un aviso parroquial, que es que el sábado que viene no va a haber newsletter de Buena Data para disfrutar del feriado y descansar un poco la máquina. Especialmente después de haber sacado Un modelo vale más que mil palabras: Procesamiento de Lenguaje Natural, el cuarto episodio de Buena Data, que podés escuchar en Spotify y el resto de las plataformas.

Ahora sí, como siempre, ¡van los links!
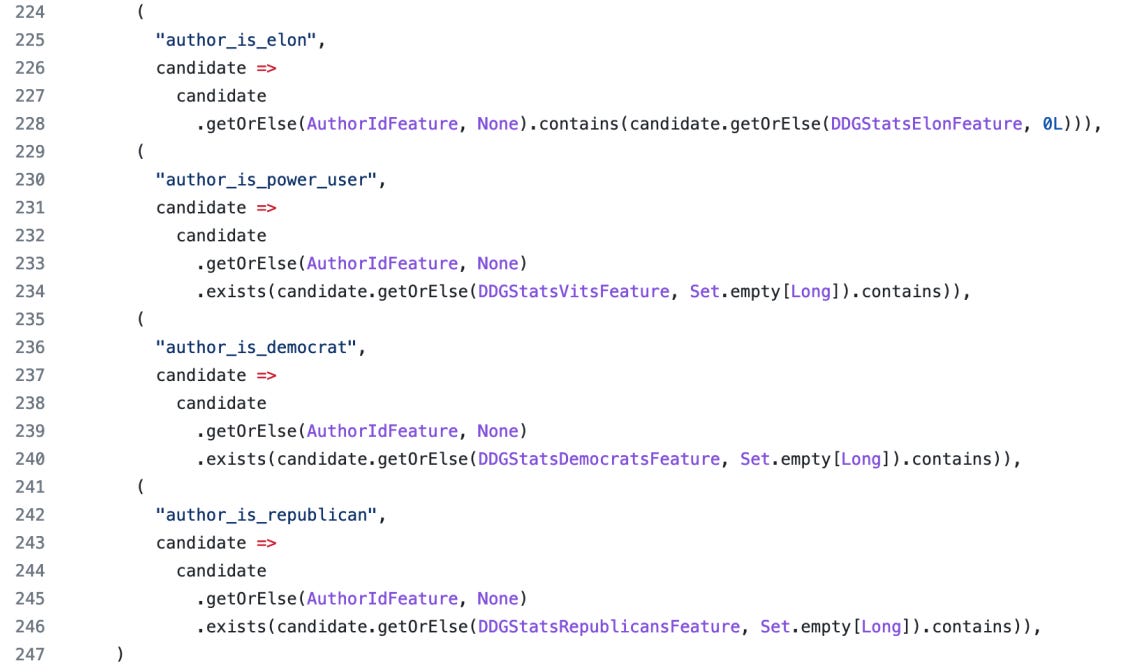
Yo les juro que intento no agarrármela con Elon (agarrármelon, digámosle) pero este muchacho me la hace difícil. Ayer cumplió una promesa histórica y liberó el código fuente del algoritmo de Twitter, y quienes se tomaron el tiempo de mirarlo encontraron magias como esta:

El tipo tiene, como se dice en la práctica, hardcodeado que si el autor del tweet es él mismo el algoritmo haga ciertas cosas. Lo mismo aplica si el autor es demócrata o repúblicano, o “power user”. Hay que ver qué otras perlitas encuentra la gente en estos días, y si tenés ganas de bucear, acá tenés el repo de código.
En sus teléfonos de alta gama, Samsung afirma estar usando IA para “mejorar la calidad de las fotos de la Luna”, cuando en realidad está pegando fotos de stock. La investigación es una locura hermosa que podés ver acá.
“¿Qué vería un viajero del tiempo si le mostraran fotos de guerreros y soldados a lo largo de la historia sacándose una selfie y sonriendo?” fue la pregunta que intentaron contestar con Midjourney (uno de los algoritmos para generación de imágenes), y que dio lugar a un estudio interesantísimo sobre qué es una sonrisa para cada cultura, y cómo hasta en estos ejemplos se pueden ver sesgos raciales en los datos de entrenamiento. Por acá tenés el artículo completo.
Una de las mejores ediciones de este espacio por lejos. Gracias por tanta buena data ♡